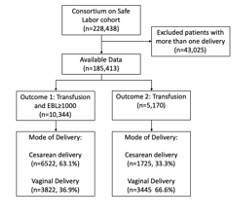
Objectives: To improve PPH prediction and to compare machine learning and traditional statistical methods. Design: Cross-sectional Setting: Deliveries across US hospitals Population: Deliveries across 12 US hospitals from the 2002-2008 Consortium for Safe Labor dataset Method: We developed models using the Consortium for Safe Labor dataset. Fifty antepartum and intrapartum characteristics and hospital characteristics were included. Logistic regression, support vector machines, multi-layer perceptron, random forest, and gradient boosting were used to generate prediction models. Receiver operating characteristic area under the curve (ROC-AUC) and precision/recall area under the curve (PR-AUC) were used to compare performance. Main Outcome Measure: The primary outcome was transfusion of blood products or PPH (estimated blood loss ≥1,000mL). The secondary outcome was transfusion of any blood products. Results: Among 228,438 births, 5,760 women (3.1%) had a postpartum hemorrhage, 5,170 women (2.8%) had a transfusion, and 10,344 women (5.6%) met criteria for the transfusion-PPH composite. Models predicting transfusion-PPH composite using antepartum and intrapartum features had the best positive predictive values with the gradient boosting machine learning model performing best overall (ROC-AUC=0.833, 95% CI [0.828-0.838]; PR-AUC=0.210 95% CI [0.201-0.220]). The most predictive features in the gradient boosting model predicting transfusion-PPH composite were mode of delivery, oxytocin incremental dose for labor(mU/min), intrapartum tocolytic use, presence of anesthesia nurse, and hospital type. Conclusion: Machine learning offers higher discrimination than logistic regression in predicting PPH. The CSL dataset may not be optimal for analyzing risk due to strong subgroup effects, which decreases accuracy and limits generalizability.